I have been writing a gbXML parser in Node.js recently and experimenting with the tessellation of complex polygons into a renderable triangle mesh. I started out using libtess.js as it has a dead-simple API (same as OpenGL GLU) and supports 3D polygons straight out of the box. It has easily handled everything I have thrown at it thus far and has proved to be a pretty good solution.
However, I have also been looking at Javascript Clipper for some related work on polygonal shadow projection and had seen some references to the earcut library which was supposed to be a much faster tessellator. As time is money, especially on a server, I thought that I would see if I could get it working and maybe compare speeds against libtess.js.
From my reading on the matter, a general consensus seems to be that libtess.js is the benchmark in terms of overall stability and robustness, but the cost for that is a bit of speed. On the other hand, earcut.js is not quite as robust, though still pretty good at all but a few outlying cases, but is blazingly fast.
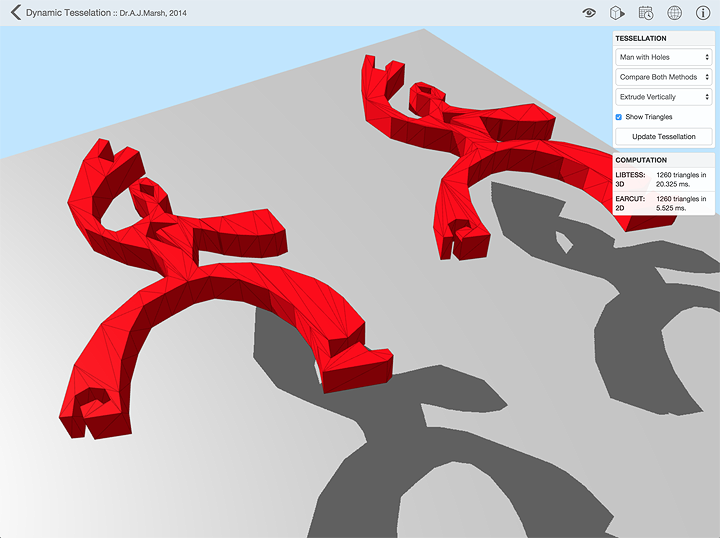
The Tessellation App
I managed to put together the above demonstration app using WebGL that shows the two tessellation algorithms in operation and allows you to visually compare the results. To make things a bit more interesting, it can extrude the polygons and tessellate all of the faces. I also added a simple user interface that lets you select from a small number of test cases and displays the triangle count and computation time for each method. The rest of this post is a bit more detail on the actual implementation and some of my stumbles along the way.
Implementation Issues
My initial implementation of earcut.js and some experiments with 2D polygons looked really promising. However, getting it to deal with 3D polygons had me utterly stumped for quite a while.
My theory was simply to use a quaternion to rotate each polygon flat in the XY plane, tessellate to generate 2D triangles in X and Y, then invert the quaternion and rotate the triangles back into place. However, this resulted in what looked like a random explosion of triangular shards. I spent a good few hours tracking the process through and comparing each step with manual calculations, but there seemed absolutely no discernible logic to the final arrangement of shards. Everything looked to be going fine and all the numbers matched up until the very last step: rotating the 2D triangles back into their 3D position. I figured that if I couldn’t get this method to work here, then I probably wouldn’t be able to use the Javascript Clipper library either so my other work would also be stuck.
In the end it turned out that I’m an idiot. The resulting triangle array from earcut.js was simply using shared vertices. In my defence, this wasn’t easy to spot as the debugging console simply showed the result as a long list of [x, y, z] arrays, three for each triangle. It wasn’t in any way obvious that the vertex arrays with the same x, y and z value were often the same array, just referenced more than once in the list. It was only when I went right back to basics and only sent 2D coordinates to the tessellator did I notice that, when stepping through the final rotation vertex-by-vertex, I would occasionally see a 2D coordinate with 3 values. It was then that I twigged that I was likely applying the rotation more than once to each of the shared vertices.
It turns out that only sending it 2D coordinates was also the key to solving the problem as I could then assume that any vertex with 3 values had already been transformed, so I could ignore it. Bang - there it was. Obvious in hindsight, but that one did cost me a bit too much hair and a few too many precious hours pulling it out.
Comparative Analysis
The next step was comparing computation times with libtess. This is where the surprises really started.
The first surprise was the variation in initial calculation times as the page loads. Obviously there is so much going on in parallel when assembling the page that the very first calculation has to wait it’s turn for resources. The amount of variation was such that a good load with libtess could sometimes be faster that a bad load with earcut. This evens out for subsequent user-invoked calculations and the results become more consistent.
The second surprise was the effect of running a longer sequence of tessellations within the same script. The Javascript compiler/interpreter in Chrome, and other browsers too it seems, are constantly looking for ‘hot’ objects and functions - those that are used or called very frequently - and will attempt further optimisations on them dynamically as the script runs and it learns more about how they are used (commonalities in the types of data stored/sent, how often values change, etc). Thus, when repeating the same tessellation several times, the computation time for each reduces significantly, sometimes down to 10% of the first. How much of this is due to memory caching and how much to dynamic optimisation is for someone else to say, but the degree of speed increase achievable was certainly a surprise.
Unfortunately, in my case, the code will only be run sporadically whenever someone uploads a gbXML file so I can’t really think of any way to take best advantage of this effect. However, it is very interesting to know and directly applicable to some of my other work with ray-tracing as these comprise very long sequences of essentially the same task, so there may be specific techniques I can use to capitalise on it there.
The upshot is that, on the machines I have tested it on, the earcut.js library takes on average about one fifth (20%) of the time required by the libtess library on the same model under the same conditions. It’s pretty variable though, but you can try it a few times on different models yourself.
Change Log
0.0.1 2014-01-21
- Initial release.
Click here to comment on this page.